DataFrame
Read in data
1 | df_can = pd.read_excel('https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DV0101EN-SkillsNetwork/Data%20Files/Canada.xlsx', |
View the top 5 rows
1 | df_can.head() |
Veiw the bottom 5 rows
1 | df_can.tail() |
Get a summary of dataframe
1 | df_can.info(verbose=False) |
Get the list of column headers
1 | df_can.columns.values |
Get the list of indicies
1 | df_can.index.values |
Note: The default type of index and columns is NOT list.
1 | print(type(df_can.columns)) |
<class 'pandas.core.indexes.base.Index'>
<class 'pandas.core.indexes.range.RangeIndex'>Get the index and columns as lists
1 | df_can.columns.tolist() |
<class 'list'>
<class 'list'>View the dimensions of the dataframe
1 | # size of dataframe (rows, columns) |
Remove columns
1 | # in pandas axis=0 represents rows (default) and axis=1 represents columns. |
Rename columns
1 | df_can.rename(columns={'OdName':'Country', 'AreaName':'Continent', 'RegName':'Region'}, inplace=True) |
Add a column that sums up the total columns
1 | df_can['Total'] = df_can.sum(axis=1) |
See how many null objects
1 | df_can.isnull().sum() |
Get a quick summary of each column
1 | df_can.describe() |
Set index
1 | df_can.set_index('Country', inplace=True) |
1 | # optional: to remove the name of the index |
Select column
There are two ways to filter on a column name:
Method 1: Quick and easy, but only works if the column name does NOT have spaces or special characters.
1 | df.column_name |
Method 2: More robust, and can filter on multiple columns.
1 | df['column'] |
1 | df[['column 1', 'column 2']] |
1 | df_can.Country # returns a series |
1 | df_can[['Country', 1980, 1981, 1982, 1983, 1984, 1985]] # returns a dataframe |
Select row
There are main 3 ways to select rows:
1 | df.loc[label] |
after set the index
Example: Let’s view the number of immigrants from Japan (row 87) for the following scenarios:
1 | 1. The full row data (all columns) |
1 | # 1. the full row data (all columns) |
Sort on a column
1 | #inplace = True paramemter saves the changes to the original df_can dataframe |
Convert the column names into strings
1 | df_can.columns = list(map(str, df_can.columns)) |
1 | # declare a variable that will allow us to easily call upon the full range of years |
Filtering based on a criteria
To filter the dataframe based on a condition, we simply pass the condition as a boolean vector.
For example, Let’s filter the dataframe to show the data on Asian countries (AreaName = Asia)
1 | # 1. create the condition boolean series |
Transpose the dataframe
1 | df_CI = df_CI.transpose() |
Groupby
The general process of groupby involves the following steps:
- Split: Splitting the data into groups based on some criteria.
- Apply: Applying a function to each group independently:
.sum()
.count()
.mean()
.std()
.aggregate()
.apply()
.etc.. - Combine: Combining the results into a data structure.
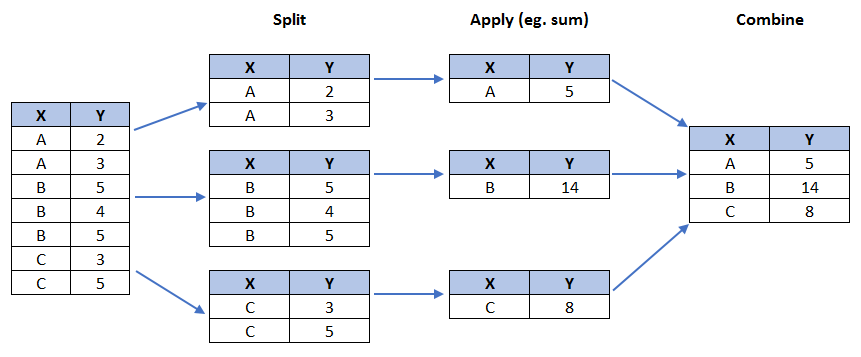
1 | # group countries by continents and apply sum() function |
polyfit()
Get the equation of line of best fit. We will use Numpy‘s polyfit() method by passing in the following:
x: x-coordinates of the data.y: y-coordinates of the data.deg: Degree of fitting polynomial. 1 = linear, 2 = quadratic, and so on.
1 | x = df_tot['year'] # year on x-axis |
array([ 5.56709228e+03, -1.09261952e+07])The output is an array with the polynomial coefficients, highest powers first. Since we are plotting a linear regression y= a*x + b, our output has 2 elements [5.56709228e+03, -1.09261952e+07] with the the slope in position 0 and intercept in position 1.
1 | df_tot.plot(kind='scatter', x='year', y='total', figsize=(10, 6), color='darkblue') |

Visualization
1 | # %matplotlib inline #强制渲染 新窗口 不可添加新元素 |
Colors available
1 | import matplotlib |
Two types of plotting
As we discussed in the video lectures, there are two styles/options of ploting with matplotlib. Plotting using the Artist layer and plotting using the scripting layer.
Option 1: Scripting layer (procedural method) - using matplotlib.pyplot as ‘plt’
You can use plt i.e. matplotlib.pyplot and add more elements by calling different methods procedurally; for example, plt.title(...) to add title or plt.xlabel(...) to add label to the x-axis.
1 | # Option 1: This is what we have been using so far |
Option 2: Artist layer (Object oriented method) - using an Axes instance from Matplotlib (preferred)
You can use an Axes instance of your current plot and store it in a variable (eg. ax). You can add more elements by calling methods with a little change in syntax (by adding “_set__” to the previous methods). For example, use ax.set_title() instead of plt.title() to add title, or ax.set_xlabel() instead of plt.xlabel() to add label to the x-axis.
This option sometimes is more transparent and flexible to use for advanced plots (in particular when having multiple plots).
1 | # option 2: preferred option with more flexibility |
Subplots
To visualize multiple plots together, we can create a figure (overall canvas) and divide it into subplots, each containing a plot. With subplots, we usually work with the artist layer instead of the scripting layer.
Typical syntax is :
1 | fig = plt.figure() # create figure |
Where
nrowsandncolsare used to notionally split the figure into (nrows*ncols) sub-axes,plot_numberis used to identify the particular subplot that this function is to create within the notional grid.plot_numberstarts at 1, increments across rows first and has a maximum ofnrows*ncolsas shown below.
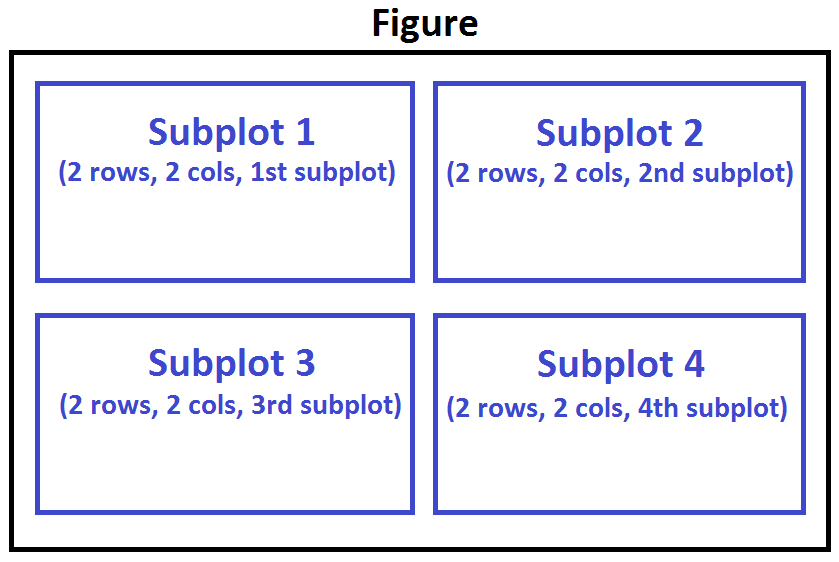
We can then specify which subplot to place each plot by passing in the ax paramemter in plot() method as follows:
1 | fig = plt.figure() # create figure |
Tip regarding subplot convention
In the case when nrows, ncols, and plot_number are all less than 10, a convenience exists such that the a 3 digit number can be given instead, where the hundreds represent nrows, the tens represent ncols and the units represent plot_number. For instance,
1 | subplot(211) == subplot(2, 1, 1) |
produces a subaxes in a figure which represents the top plot (i.e. the first) in a 2 rows by 1 column notional grid (no grid actually exists, but conceptually this is how the returned subplot has been positioned).
Prepping Data
Let’s download, import and clean our primary Canadian Immigration dataset using pandas read_excel() method for any visualization.
1 | df_can = pd.read_excel('https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DV0101EN-SkillsNetwork/Data%20Files/Canada.xlsx', |
——————————————————————–
Line plots
1 | haiti = df_can.loc['Haiti', years] # passing in years 1980 - 2013 to exclude the 'total' column |
pandas automatically populated the x-axis with the index values (years), and the y-axis with the column values (population). However, notice how the years were not displayed because they are of type string. Therefore, let’s change the type of the index values to integer for plotting.
1 | haiti.plot(kind='line') |
Quick note on x and y values in plt.text(x, y, label):
Since the x-axis (years) is type ‘integer’, we specified x as a year. The y axis (number of immigrants) is type ‘integer’, so we can just specify the value y = 6000.
1 | plt.text(2000, 6000, '2010 Earthquake') # years stored as type int |
If the years were stored as type ‘string’, we would need to specify x as the index position of the year. Eg 20th index is year 2000 since it is the 20th year with a base year of 1980.
1 | plt.text(20, 6000, '2010 Earthquake') # years stored as type int |
Area plots
1 | # get the top 5 entries |
The unstacked plot has a default transparency (alpha value) at 0.5. We can modify this value by passing in the alpha parameter.2The unstacked plot has a default transparency (alpha value) at 0.5. We can modify this value by passing in the alpha parameter.
1 | df_top5.plot(kind='area', |
Histrograms
1 | # np.histogram returns 2 values |
[178 11 1 2 0 0 0 0 1 2]
[ 0. 3412.9 6825.8 10238.7 13651.6 17064.5 20477.4 23890.3 27303.2
30716.1 34129. ]By default, the histrogram method breaks up the dataset into 10 bins.
1 | df_can['2013'].plot(kind='hist', figsize=(8, 5)) |
Notice that the x-axis labels do not match with the bin size. This can be fixed by passing in a xticks keyword that contains the list of the bin sizes, as follows:
1 | # 'bin_edges' is a list of bin intervals |
Side Note: We could use df_can['2013'].plot.hist(), instead. In fact, throughout this lesson, using some_data.plot(kind='type_plot', ...) is equivalent to some_data.plot.type_plot(...). That is, passing the type of the plot as argument or method behaves the same.
See the pandas documentation for more info http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.plot.html.
We can also plot multiple histograms on the same plot.
1 | # transpose dataframe |
Let’s make a few modifications to improve the impact and aesthetics of the previous plot:
- increase the bin size to 15 by passing in
binsparameter - set transparency to 60% by passing in
alphaparamemter - label the x-axis by passing in
x-labelparamater - change the colors of the plots by passing in
colorparameter
1 | # let's get the x-tick values |
If we do no want the plots to overlap each other, we can stack them using the stacked paramemter. Let’s also adjust the min and max x-axis labels to remove the extra gap on the edges of the plot. We can pass a tuple (min,max) using the xlim paramater, as show below.
1 | count, bin_edges = np.histogram(df_t, 15) |
Bar charts
To create a bar plot, we can pass one of two arguments via kind parameter in plot():
kind=barcreates a vertical bar plotkind=barhcreates a horizontal bar plot
Vertical bar plot
In vertical bar graphs, the x-axis is used for labelling, and the length of bars on the y-axis corresponds to the magnitude of the variable being measured. Vertical bar graphs are particuarly useful in analyzing time series data. One disadvantage is that they lack space for text labelling at the foot of each bar.
1 | # step 1: get the data |
Horizontal Bar Plot
Sometimes it is more practical to represent the data horizontally, especially if you need more room for labelling the bars. In horizontal bar graphs, the y-axis is used for labelling, and the length of bars on the x-axis corresponds to the magnitude of the variable being measured. As you will see, there is more room on the y-axis to label categetorical variables.
1 | # generate plot |
Annotate
Let’s annotate this on the plot using the annotate method of the scripting layer or the pyplot interface. We will pass in the following parameters:
s: str, the text of annotation.xy: Tuple specifying the (x,y) point to annotate (in this case, end point of arrow).xytext: Tuple specifying the (x,y) point to place the text (in this case, start point of arrow).xycoords: The coordinate system that xy is given in - ‘data’ uses the coordinate system of the object being annotated (default).arrowprops: Takes a dictionary of properties to draw the arrow:arrowstyle: Specifies the arrow style,'->'is standard arrow.connectionstyle: Specifies the connection type.arc3is a straight line.color: Specifes color of arror.lw: Specifies the line width.
I encourage you to read the Matplotlib documentation for more details on annotations:
http://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.annotate.
1 | df_iceland.plot(kind='bar', figsize=(10, 6), rot=90) # rotate the xticks(labelled points on x-axis) by 90 degrees |
 Let’s also annotate a text to go over the arrow. We will pass in the following additional parameters:
Let’s also annotate a text to go over the arrow. We will pass in the following additional parameters:
rotation: rotation angle of text in degrees (counter clockwise)va: vertical alignment of text [‘center’ | ‘top’ | ‘bottom’ | ‘baseline’]ha: horizontal alignment of text [‘center’ | ‘right’ | ‘left’]
1 | df_iceland.plot(kind='bar', figsize=(10, 6), rot=90) |

Pie charts
You are most likely already familiar with pie charts as it is widely used in business and media. We can create pie charts in Matplotlib by passing in the kind=pie keyword.
We will pass in kind = 'pie' keyword, along with the following additional parameters:
autopct- is a string or function used to label the wedges with their numeric value. The label will be placed inside the wedge. If it is a format string, the label will befmt%pct.startangle- rotates the start of the pie chart by angle degrees counterclockwise from the x-axis.shadow- Draws a shadow beneath the pie (to give a 3D feel).
1 | # group countries by continents and apply sum() function |

The above visual is not very clear, the numbers and text overlap in some instances. Let’s make a few modifications to improve the visuals:
- Remove the text labels on the pie chart by passing in
legendand add it as a seperate legend usingplt.legend(). - Push out the percentages to sit just outside the pie chart by passing in
pctdistanceparameter. - Pass in a custom set of colors for continents by passing in
colorsparameter. - Explode the pie chart to emphasize the lowest three continents (Africa, North America, and Latin America and Carribbean) by pasing in
explodeparameter.
1 | colors_list = ['gold', 'yellowgreen', 'lightcoral', 'lightskyblue', 'lightgreen', 'pink'] |

Box plots
A box plot is a way of statistically representing the distribution of the data through five main dimensions:
- Minimun: Smallest number in the dataset.
- First quartile: Middle number between the
minimumand themedian. - Second quartile (Median): Middle number of the (sorted) dataset.
- Third quartile: Middle number between
medianandmaximum. - Maximum: Highest number in the dataset.
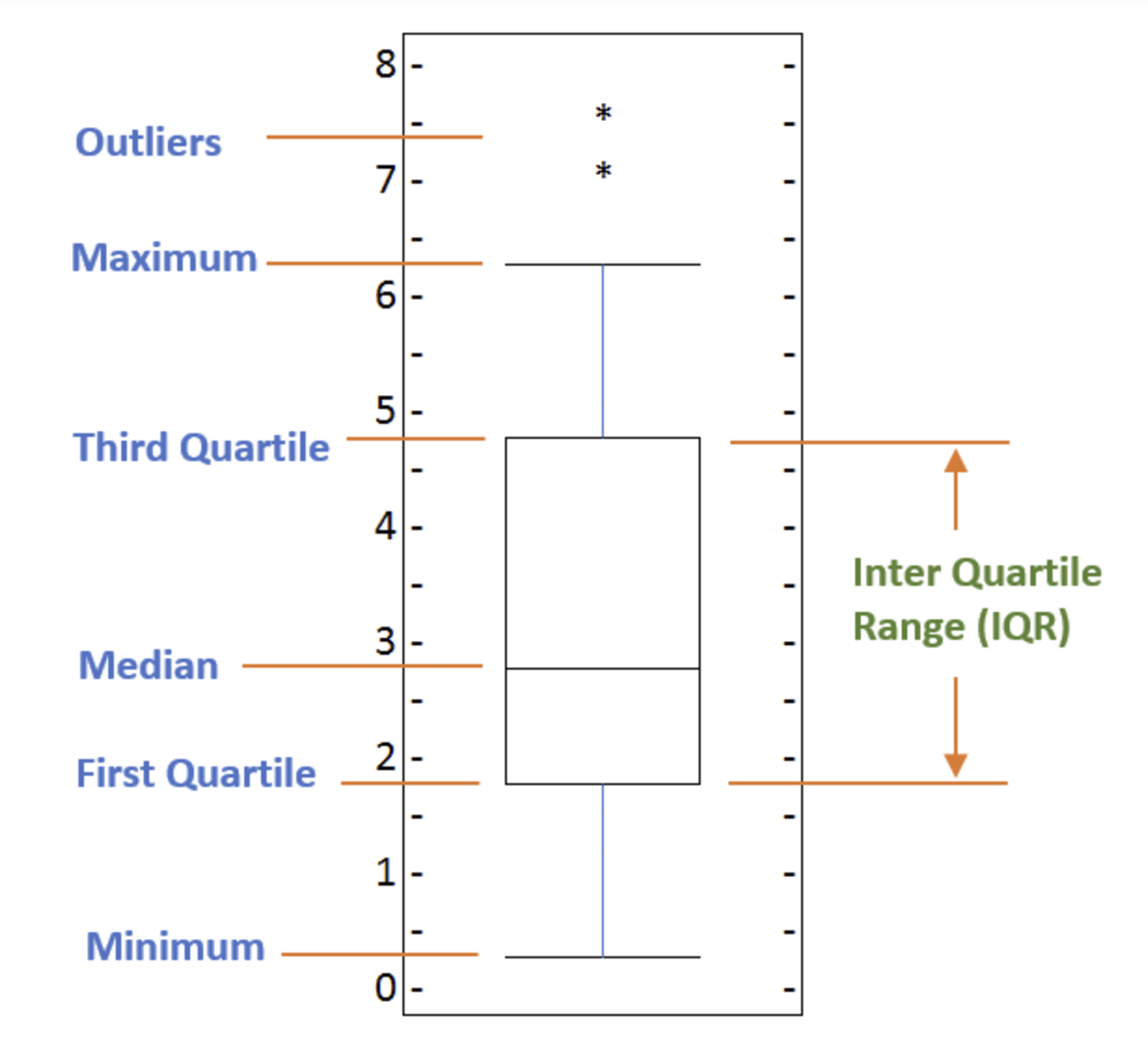
To make a box plot, we can use kind=box in plot method invoked on a pandas series or dataframe.
1 | # to get a dataframe, place extra square brackets around 'Japan'. |
P.S. We can view the actual numbers by calling the describe() method on the dataframe.
1 | df_japan.describe() |

If you prefer to create horizontal box plots, you can pass the vert parameter in the plot function and assign it to False. You can also specify a different color in case you are not a big fan of the default red color.
horizontal box plots
1 | df_CI= df_can.loc[['China', 'India'], years].transpose() |

1 | df_top15 = df_can.sort_values(['Total'], ascending=False, axis=0).head(15) |

The box plot is an advanced visualizaiton tool, and there are many options and customizations that exceed the scope of this lab. Please refer to Matplotlib documentation on box plots for more information.
Scatter plots
1 | # we can use the sum() method to get the total population per year |
We can create a scatter plot set by passing in kind='scatter' as plot argument. We will also need to pass in x and y keywords to specify the columns that go on the x- and the y-axis.
1 | df_tot.plot(kind='scatter', x='year', y='total', figsize=(10, 6), color='darkblue') |
Bubble plots
A bubble plot is a variation of the scatter plot that displays three dimensions of data (x, y, z). The datapoints are replaced with bubbles, and the size of the bubble is determined by the third variable ‘z’, also known as the weight. In maplotlib, we can pass in an array or scalar to the keyword s to plot(), that contains the weight of each point.
Let’s start by analyzing the effect of Argentina’s great depression.
Argentina suffered a great depression from 1998 - 2002, which caused widespread unemployment, riots, the fall of the government, and a default on the country’s foreign debt. In terms of income, over 50% of Argentines were poor, and seven out of ten Argentine children were poor at the depth of the crisis in 2002.
Let’s analyze the effect of this crisis, and compare Argentina’s immigration to that of it’s neighbour Brazil. Let’s do that using a bubble plot of immigration from Brazil and Argentina for the years 1980 - 2013. We will set the weights for the bubble as the normalized value of the population for each year.
Step 1: Get the data for Brazil and Argentina. Like in the previous example, we will convert the Years to type int and bring it in the dataframe.2Step 1: Get the data for Brazil and Argentina. Like in the previous example, we will convert the Years to type int and bring it in the dataframe.
1 | df_can_t = df_can[years].transpose() # transposed dataframe |
Step 2: Create the normalized weights.
There are several methods of normalizations in statistics, each with its own use. In this case, we will use feature scaling to bring all values into the range [0,1]. The general formula is:
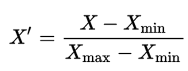
where X is an original value, X' is the normalized value. The formula sets the max value in the dataset to 1, and sets the min value to 0. The rest of the datapoints are scaled to a value between 0-1 accordingly.
1 | # normalize Brazil data |
Step 3: Plot the data.
- To plot two different scatter plots in one plot, we can include the axes one plot into the other by passing it via the
axparameter. - We will also pass in the weights using the
sparameter. Given that the normalized weights are between 0-1, they won’t be visible on the plot. Therefore we will:- multiply weights by 2000 to scale it up on the graph, and,
- add 10 to compensate for the min value (which has a 0 weight and therefore scale with x2000).
1 | # Brazil |

Seaborn - Regression plots
Seaborn is a Python visualization library based on matplotlib. It provides a high-level interface for drawing attractive statistical graphics. You can learn more about seaborn by following this link and more about seaborn regression plots by following this link.
1 | # import library |
With seaborn, generating a regression plot is as simple as calling the regplot function.
1 | import seaborn as sns |

Try to pretty it
- blow up the plot a little bit so that it is more appealing to the sight.
- increase the size of markers so they match the new size of the figure, and add a title and x- and y-labels.
- increase the font size of the tickmark labels, the title, and the x- and y-labels so they don’t feel left out!
1
2
3
4
5
6
7plt.figure(figsize=(15, 10))
sns.set(font_scale=1.5)
ax = sns.regplot(x='year', y='total', data=df_tot, color='green', marker='+', scatter_kws={'s': 200})
ax.set(xlabel='Year', ylabel='Total Immigration')
ax.set_title('Total Immigration to Canada from 1980 - 2013')
If you are not a big fan of the purple background, you can easily change the style to a white plain background.
1 | plt.figure(figsize=(15, 10)) |

Or to a white background with gridlines.
1 | plt.figure(figsize=(15, 10)) |

Waffle charts
写到这里写到死机,然后忘保存了 :( :( :(
为了防止这样的情况再次发生,以及(暂时)懒得重新修辞和组合语句,就另开一篇博客放上没仔细修改的原notebook,链接here 有时间会重新组织下语言
Word Clouds
:( :( :( 链接here 有时间会重新组织下语言
Folium
For there are so many contents for Folium, so I will open a new bolg here.